
Wenn es um künstliche Intelligenz oder maschinelles Lernen geht, fällt neben den neuronalen Netzen besonders oft der Begriff „Support Vector Machine“ oder kurz SVM. Doch was kann das Verfahren und wie funktioniert es? Da ich mich in meiner Doktorarbeit mit der SVM beschäftigt habe, versuche ich mich heute mal an einer sehr einfachen Erklärung.
Ins Deutsche übersetzt bedeutet der Begriff „Support Vector Machine“ so viel wie“Stützvektormaschine“. Einen Stützvektor braucht man (neben dem oder den Richtungsvektoren) um die Lage einer Ebene im Raum zu beschreiben. Und genau diese Ebenen spielen bei der SVM eine wichtige rolle, wie wir in den zwei Beispielen sehen.
Die Support Vector Machine zur Klassifizierung
Die SVM wird gern für Klassifizierungsprobleme herangezogen also um Datenpunkte in Klassen oder Gruppen einzuteilen. Hierzu wird für n-dimensionale (z. B. 2-dimensionale) Punktemengen unterschiedlicher Kategorien eine Trennebene errechnet, die den maximalen Abstand zu den nächsten Punkten der zu trennenden Kategorie aufweist (Bild 1). Im dargestellten Beispiel sind in einem 1-dimensionalen Raum Punktemengen zweier Kategorien durch eine 0-dimensionale Trennebene (hier eher Trennpunkt) getrennt. Jeder neue Punkt könnte nun durch die Trennebene einer Kategorie zugeordnet werden.

Die Besonderheit der SVM liegt jedoch nicht in der Trennebene, sondern darin, dass Punktemengen eines n-dimensionalen Raumes, die sich nicht durch eine n-1-dimensionale Ebene (Hyperebene genannt) trennen lassen, in einen höherdimensionalen Raum transformiert werden können, in dem die Punkte dann trennbar werden. Im dargestellten Beispiel in Bild 2 sind Punktemengen zweier Klassen (Raute und Quadrat) im vorliegenden 1-dimensionalen Raum nicht voneinander trennbar, da eine Punkteklasse (Quadrat) die andere (Raute) umschließt.

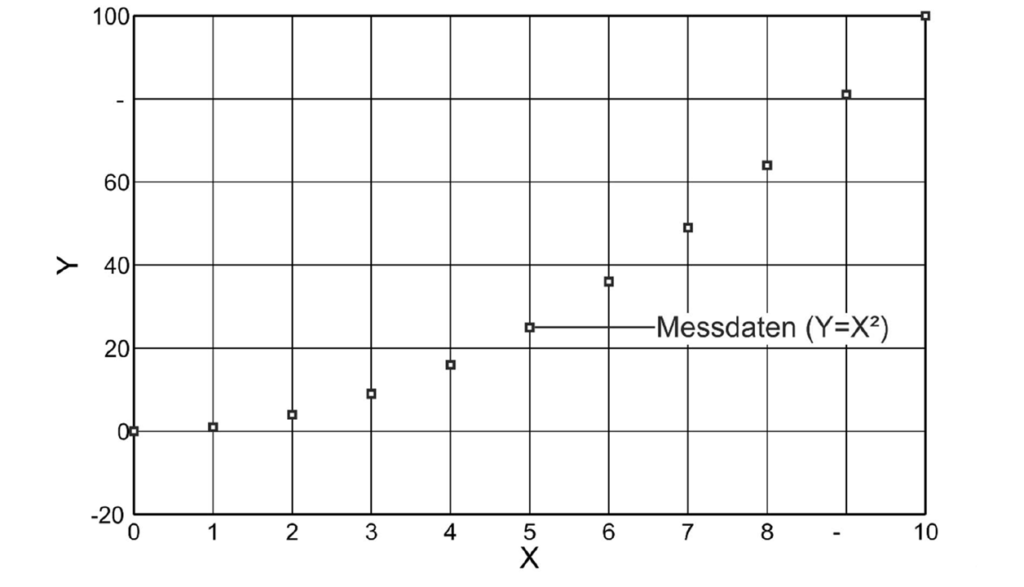
Um die Punktemengen dennoch mithilfe linearer Ebenen zu trennen, werden diese in einen 2-dimensionalen Raum überführt (Bild 3). Die zweite Dimension wird dabei durch eine feste Bedingung in Form einer Funktion erstellt (im Beispiel Y=X²).
Aufgrund der entstandenen Krümmung lassen sich die Punkteklassen jetzt voneinander durch eine 1-dimensionale lineare Ebene trennen. Die zu trennenden Punkte können zur Lösungsfindung in Räume beliebiger Dimensionen-Anzahl überführt werden. Diese Methode wird als Kerneltrick bezeichnet. Da die trennende Hyperebene im n-dimensionalen Raum immer durch einen Stützvektor und n-1 Richtungsvektoren beschrieben wird, ist das Verfahren sehr einfach und ressourcenarm automatisierbar und wird daher gern zum maschinellen Lernen verwendet. Die SVM ist in der Regel auch performanter als beispielsweise ein neuronales Netz .
Die Support Vector Machine zur Regression
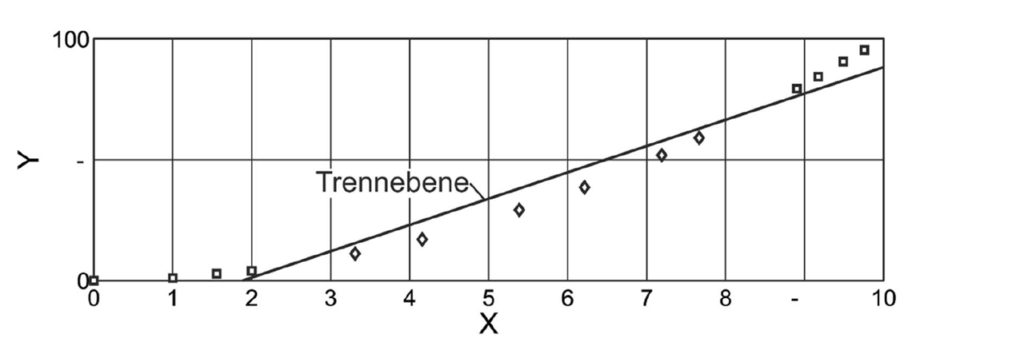
Das Besondere an der SVM ist aber, dass der Kerneltrick nicht nur zur Klassifikation, sondern auch zur Regression verwendet werden kann, um den stetigen Zusammenhang zwischen Ein- und Ausgangsvariablen zu analysieren und zu modellieren. Bild 4 zeigt Messdaten mit einem polynominalen Zusammenhang zwischen der Eingangsvariablen X und der Ausgangsvariablen Y. Die beispielhafte lineare Regression liefert im 2-dimensionalen kein Modell mit akzeptabler Genauigkeit, denn hier würde einfach nur eine Gerade herauskommen.
Mit der exemplarischen Bedingung Z = X * Y kann die Punkte-Menge jedoch, wie in Bild 5 dargestellt, in den 3-dimensionalen Raum transformiert werden.
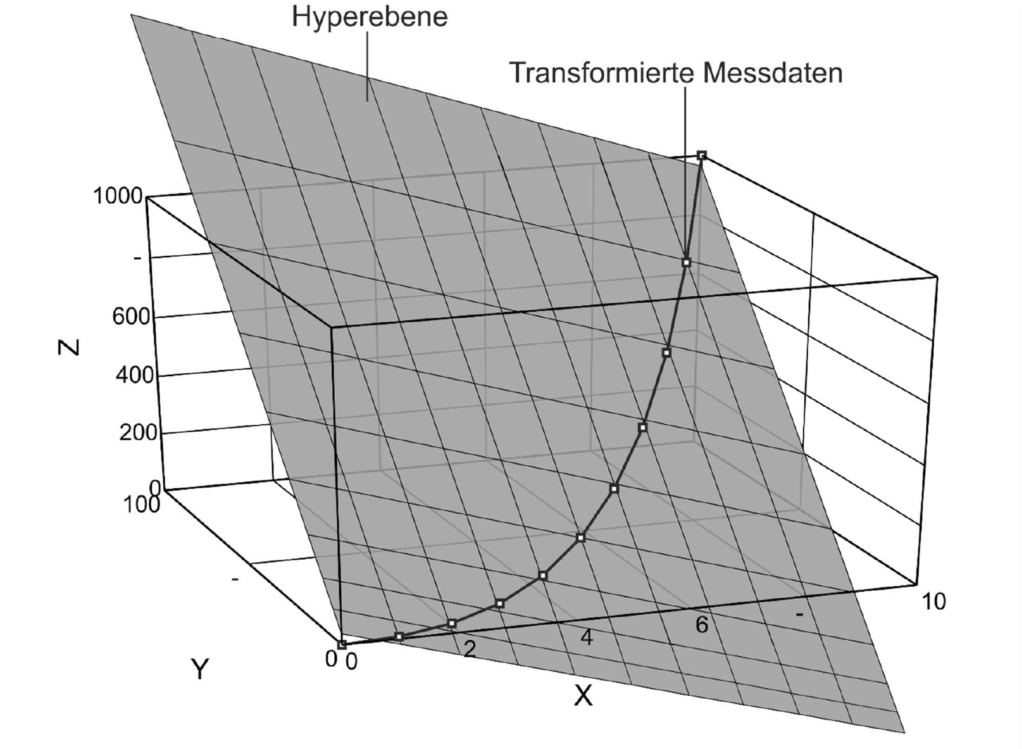
Im nächsten Schritt wird eine Ebene erzeugt, auf der im Idealfall alle Punkte liegen. Analog zur Regression, z. B. mithilfe der Methode kleinster Fehlerquadrate, sind jedoch auch bei der Hyperebene Abweichungen möglich und kommen in der Realität vor. Im dargestellten Beispiel ist die vorliegende Ebene durch folgende Formel beschreibbar.

Durch Einsetzen der Nebenbedingung Z = X * Y und Auflösen der Formel nach Y kann die Formel erzeugt werden, die den Zusammenhang zwischen den Eingangsvariablen X und den Ausgangsvariablen Y beschreibt:

Das Modellierungsergebnis ist grafisch im letzten Bild dargestellt. Der reellen Funktion Y=X² entspricht das Modell der Support Vector Machine deutlich besser als die Regressionsgerade.
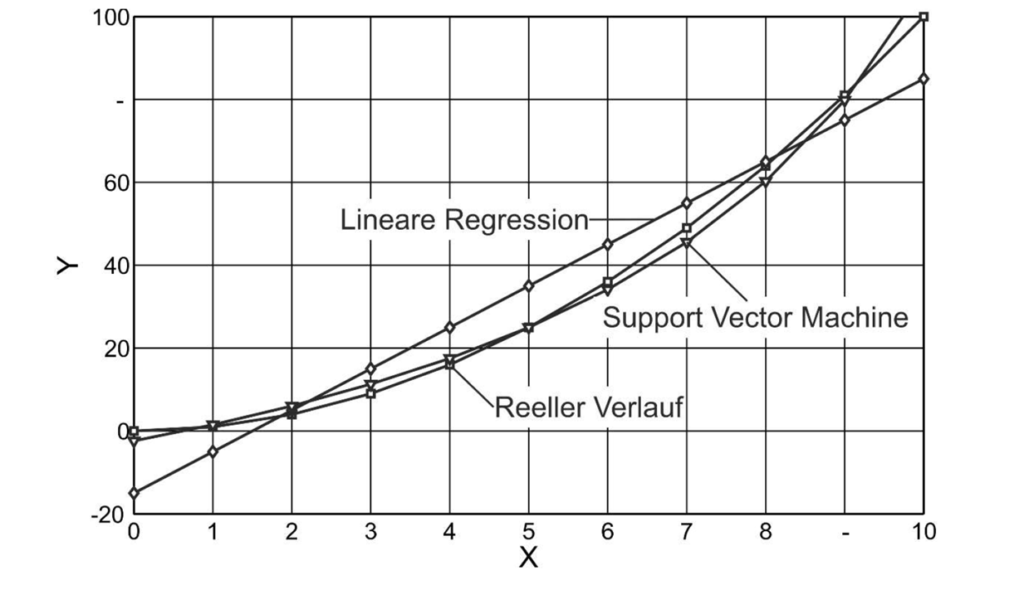
Die Genauigkeit der Support Vector Maschine kann durch Transformation der Punkte in noch höherdimensionale Räume verbessert werden. Zudem können neben der Regression auch Modelle mithilfe von Polynom- und Radialbasisfunktionen gebildet werden, was die Flexibilität und die Genauigkeit weiter erhöht. In der Praxis sind die Nebenbedingungen allerdings etwas komplizierter als die, die ich verwendet habe. Das Prinzip bleibt aber gleich.
Wer sich selbst einmal an der SVM versuchen möchte, dem lege ich die Software KNIME ans Herz mit der auch ich meine ersten Gehversuche in dem Thema gemacht habe. Wer lieber ein eigenes Programm schreiben möchte, kann die Bibliothek LibSVM für seine verwenden, die es eigentlich für jede Programmiersprache und auch für Matlab gibt.
Schreibe einen Kommentar